Introduction
Last year our team released a public beta version of Talkback, an infosec resource aggregator we’d been developing internally. Throughout 2023 we chipped away at adding new features, implementing bug-fixes, and also released an API. In this post, we’ll provide background on what Talkback is, how it works, then show-case some of its features and GraphQL API examples.
Background
Keeping up with the high volume of infosec news and technical content has become increasingly challenging each year. Nowadays to keep up with the constant stream of content, many choose to combine a handful of news aggregation sites, infosec newsletters and podcasts, messaging apps, and for some miserable folks out there, even succumbing to infosec Twitter. There’s also those regular times where you need to hunt down that resource you read a few months ago about $thing, hoping a few terms and some Google-fu will get lucky.
While there’s a bunch of sites around that aggregate infosec resources, they often lack certain features and flexibility. One issue is some rely on manual curation or moderation of feeds and content, which can impact timeliness and also create filter bubbles, and then many are too simple in their design, with a small data-set associated to resources, such as what you’d see in a RSS feed, and consequently the flexibility around use-cases becomes constrained.
Because of this, we decided to design and develop our own tool to use to help make our lives easier and give some of the features we longed for. In the following sections we’ll talk about how Talkback works and what you can do with it.
How Talkback works
Talkback sets out to tap into numerous data sources to collect resources, then performs a few types of content analysis to both clean and enrich the data-set to ultimately create some useful functionality for the end-user via the UI and API.
Data feeds
When we got started, we chose to leverage r/netsec as an initial data-seed, because we wanted some initial data that was moderated, security-focused, and went back some years. Using Google BigQuery, it was trivial to load all historical resources going back to around 2007, albeit this data-set was quite limited.
From this point, we built out a number of content analysis modules and evolved how data-feeds operate with some smarts baked in. This includes:
-
Adding a concept of
Curators, that involves actively monitoring several popular infosec content curators. This helps to ensure a level of coverage, but more importantly serves as a way to train the system via the manual vetting by the curators. The curators list includes The Risky Business podcast, ThinkstScapes Quarterly, and tl;dr sec. -
Loading popular conference archives, such as Blackhat and Usenix. All presentation resources are parsed and indexed, with a little help referencing content on Thinkst Citation.
-
Monitoring dozens of social media sites and feeds such as popular infosec subreddits and users/researchers on social media who focus exclusively on reposting infosec-focused content.
-
Identifying and tracking thousands of infosec RSS feeds, where we’ve built logic to actively monitor blog feeds based on previously seen trends.
Content analysis summary
When new resources come into the system, a series of content analysis modules are run to both normalise data and also enrich the data-set. For web-content the content is determined and extracted, and for file-types such as PDFs a third-party library is used. Ultimately the text-based content ends up being indexed in an Elasticsearch instance. Due to the nature of the web and content, there’s a big risk for Garbage in, Garbage out when building a system like Talkback, so quite a lot of time has been spent to normalise and clean data to the best of our ability.
Once data has been cleaned, a number of content enrichment modules are then run against each resource, including but not limited to:
- Wayback Machine: Save resource URL on the Wayback machine to make sure an archive is always available.
- Screenshot: Take a screenshot of the URL to give a quick visual of what the resource looks like.
- Full Text Extraction: Utilise Apache Tika to support content extraction across many formats, including PDFs and PPTs.
- Wordcloud Generation: Create a wordcloud of the content to help give a quick visual of common unique terms for the resource.
- TLDR Summary: Generate a tldr summary using OpenAI to give a 5-line summary of the resource content.
- Category Classifier: Run a multi-label classifier that uses OpenAI to determine relevant infosec categories.
- NVD Sync: Extract all infosec specific references (CVE, CWE) as tags.
- Talkback Cross-Referencing: All links in the content are looked up and cross-referenced in Talkback.
- Shodan Integration: Query Shodan for basic hosting information, such as hosting information and location.
- RSS Feed Extractor: Extract any RSS feed URLs are store them in the internal RSS library.
- Resource Ranking: A custom rank score is calculated for the resource factoring in past trends and related resources.
- Reading Time: A reading time in minutes is calculated based on the content length and word count.
- Curator Mapping: Identify if the resource has been featured by a Curator.
All of this data is then stored and associated to each resource, allowing for end-users to be able to browse, filter, and search resources within Talkback leveraging this data-set.
How to use the Talkback UI
The main page shows a list of resources, where clicking a resource opens a preview pane, with the option to navigate to the resource page to view the full details.
The Home menu in the navbar lists everything. The other menu entries are preset views:
Techlists everything but news related.Newslists only resources that are on domains that focus on news.Featuredlists only resources specifically mentionned by a curator.Savedpresents a list of bookmarks.

Talkback is designed so users don’t feel like they need to register/sign-in, and by default preferences (e.g. light/dark mode) and Saved history will be kept in Local Storage. For people who want to try the GraphQL API or if they would like their preferences/history to persist beyond local storage, they can sign-in via Google, GitHub or Email.
Search, Filters, and Views
A main goal of Talkback is to help users get to relevant and useful information quickly, and this can be done via Search or Filters in the UI.
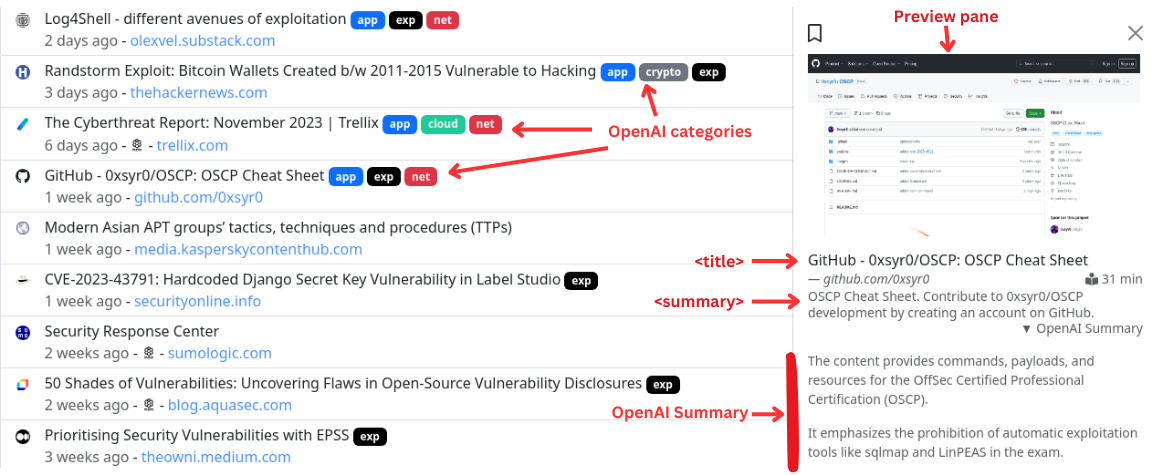
All resources are indexed in Elasticsearch and can be searched using the query string syntax. The resource <title> and <description> meta tags are also indexed. You can search only specific fields using field names in the query string, otherwise all fields are searched by default (click the help icon for syntax).
The filters can be used to:
- find specific domains/URLs
- search for the exact CVE or CWE identifier
- include/exclude types, categories or curators
- adjust the date range
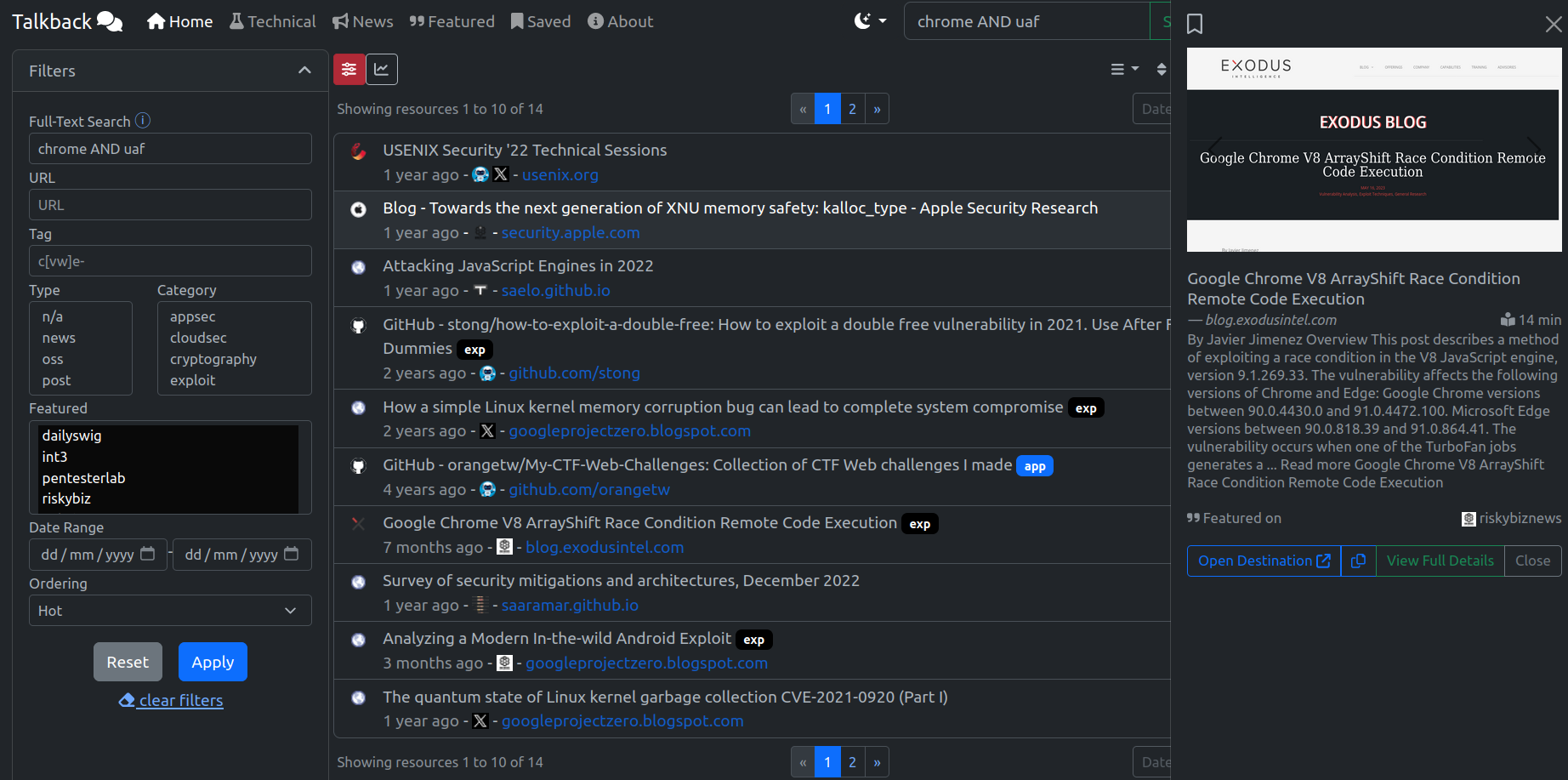
Example - Chrome UaF Resources
Consider wanting to find technical blog posts and papers that mention chrome and the bug class uaf (use after free). A simple query returns over a dozen articles sorted by its calculated `Rank` by default spanning back a few years. To sort chronologically, it's possible to use the sort icon to sort by `Date`. Clicking on a row shows the `Preview Pane` where it will show a screenshot, a summary about the content, and also note if the resource has been featured by any `Curators`.
Example - Resource View
Viewing a particular resource shows everything that's been collected about it. The following screenshot shows an example of all the key fields that are shown in the resource view.
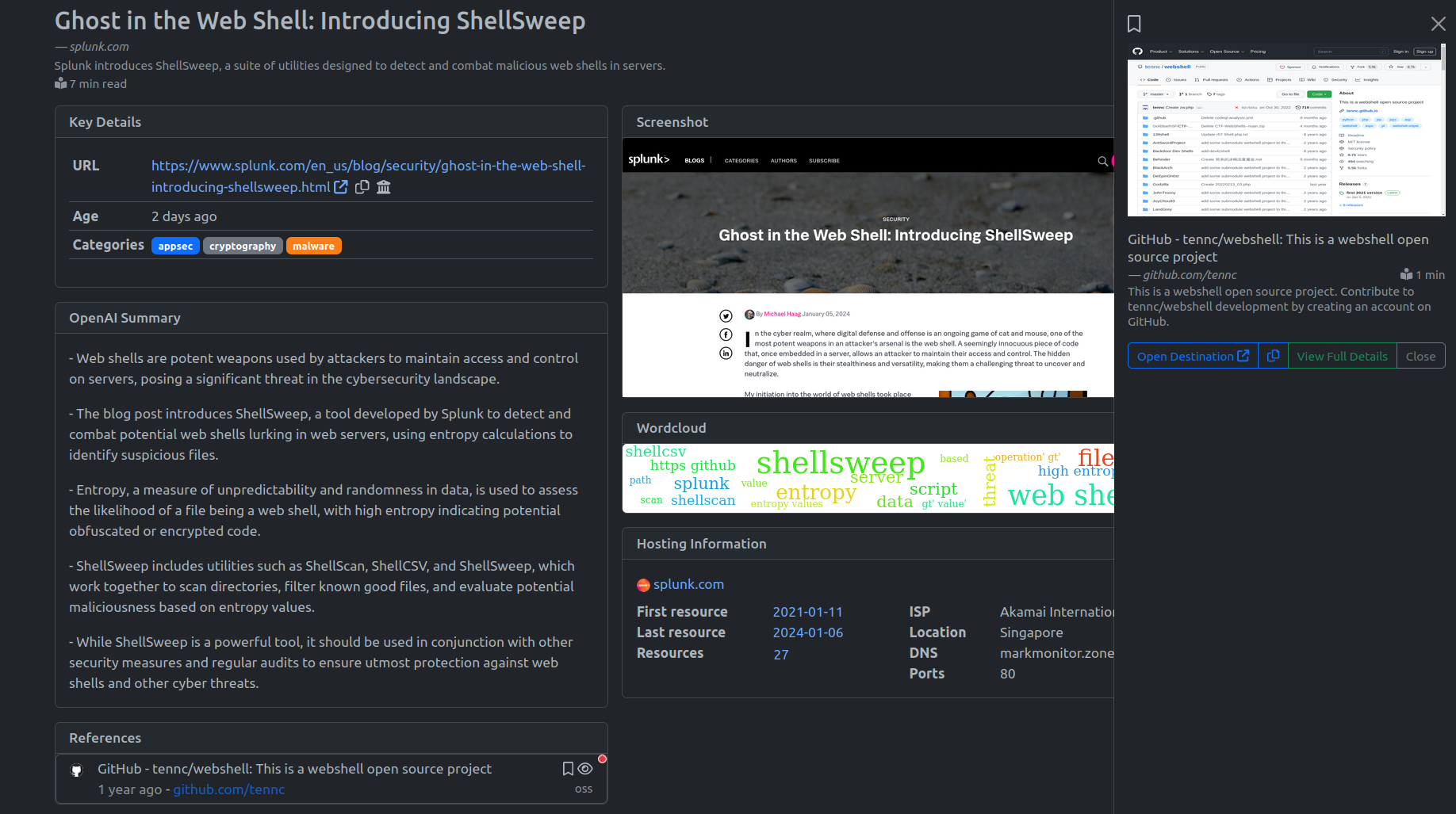
In the following section we’ll talk through some of these fields, how they’re populated, and their intended purpose.
Key Features
TLDR’s and Resource Classification via OpenAI
Talkback leverages OpenAI in a couple of ways.
Firstly, a multi-label classifier is run which assigns categories to resources as appropriate. This is done by scoring the resource against all potential categories, and then adds the categories that weight the highest. A couple of examples are if a blog post talks about reverse engineering some malware used in a targeted attack, it would likely have the mal and rev categories, and maybe the sys category too, whereas a paper released on side-channel attacks against a specific network protocol, would likely have the net and crypto categories, and maybe exp too.
The categories supported currently are:
- Reverse (rev) - References reverse engineering methodologies/tooling.
- System (sys) - References systems level security, such as operating system internals and low level system components.
- Appsec (app) - References application security concepts, methodologies, and tooling.
- Cryptography (crypto) - References cryptography concepts and algorithms.
- Exploit (exp) - References writing or demonstrating exploits or proof-of-concept code.
- Social Engineering (soceng) - References social engineering / human factors related to security.
- Industrial Systems (ics) - References industrial control systems / OT / Scada systems.
- Netsec (net) - References network technologies and protocols.
- Malware (mal) - References malware, rootkits, etc.
- Cloudsec (cloud) - References cloud technologies and cloud security concepts.
- Forensics (for) - References computer forensic terminology and tooling.
In addition, Talkback taps into OpenAI to prepare a 5-bullet point summary for each resource. This attempts to extract key points from the content in a way for a reader to quickly digest what the resource is covering, allowing for easy skim reading.
NVD Integration for CVE/CWE References
Talkback integrates with NVD to provide the latest information for the CVEs and CWEs referenced in a resource. This can then be referenced when searching or filtering resources, giving some more power to end-users, such as wanting to find all resources talking about a specific vulnerability or vulnerability class.
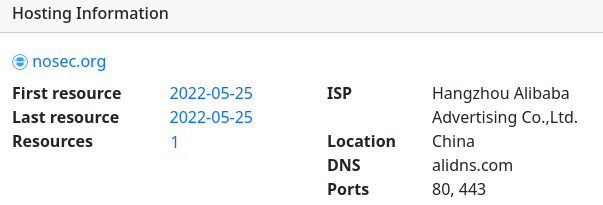
Shodan for Hosting Information
To add some additional information on where resources are hosted, some basic hosting information from Shodan is included in the resource detail page. This helps to quickly give the user an idea of the hosting provider and location of the resource, but also shows the amount of resources seen by Talkback including when it was first/last seen. This can help the user make a call whether they want to click-through to the destination or potentially visit it in a sandboxed environment to counter potential risks affecting some security researchers.
The Talkback GraphQL API
Late in 2023, we released a GraphQL API to search and query indexed resources. We chose GraphQL to give flexibility for consumers to be able to learn and explore the schema and find the right queries for their own use-cases. This will continue to expand and evolve as we build out new features and refine things. Check out the examples below as well as the API help page for more info.
Access
The API is only accessible over an authenticated user session. So you first need to sign in, then either use the in-browser GraphQL IDE or, generate an API token here and pass it via the Authorization: JWT HTTP header.
Full-Text Search
Use the resources query to search indexed resources. This is the same as using the Search feature in Talkback.
The following query will search for resources mentionning the word “log4j”:
# request
query {
resources(q:"log4j") {
edges {
node {
id
url
title
}
}
}
}
# response
{
"data": {
"resources": {
"edges": [
{
"node": {
"id": "6d7e8cb6-d097-433c-9361-441b79468ce2",
"url": "https://github.com/0xsyr0/OSCP",
"title": "GitHub - 0xsyr0/OSCP: OSCP Cheat Sheet"
}
},
--- cut ---
Note: search results are paginated
Resource Details
Use the resource query to zoom in on a specific resource.
# request
query {
resource(id:"94a9d6a2-215d-4f40-a054-bf79467ff021") {
id
title
}
}
# response
{
"data": {
"resource": {
"id": "94a9d6a2-215d-4f40-a054-bf79467ff021",
"title": "PwnAssistant - Controlling /home's via a Home Assistant RCE"
}
}
}
CVE/CWE
Search for a specific CVE or CWE by passing the exact identifier (match is case-insensitive).
query {
resources(tag:"cve-2021-26855" orderBy:"-date") {
edges {
node {
id
url
title
}
}
}
}
You can also pass extra filters.
query {
resources(tag:"cwe-79" url:"github.com" orderBy:"-rank") {
edges {
node {
id
url
rank
}
}
}
}
Searching for functions
With content fully indexed from all resources, it provides a powerful capability to be able to search for keywords, including function names and other technical terms.
A quick PoC is shown in the video below, where we use tree-sitter to retrieve the function names from a public source code repo and then query the API to discover blog posts that mention unique function names.
Conclusion
That’s all for now, we hope this post has helped provide an overview of Talkback, and sparked some ideas for how you could use it. There are still some known bugs, a lot of improvements and new features which we’ll look at working on in 2024, we’ll post periodically about new major releases of the tool, and also with examples on how we use Talkback internally.
To access Talkback via the web UI please visit https://talkback.sh/, and to get started with the GraphQL API visit https://talkback.sh/api/v1/help/.
Thanks for reading!